На нескольких проектах была похожая задачка. Хотелось людям видеть в таблице в Confluence текущие версии микросервисов, задеплоенные в k8s, да так, чтобы было разделение по контурам. Некий справочник такой, для менеджеров всяких, да и не только. В целом достаточно удобно, можно быстро глянуть, какая версия сейчас «в бою» и на вопрос разработчика микросервиса «А какая там у меня щас версия?» не идти в кубер, а слать разработчика прямиком в таблицу.
Давайте обрисуем ТЗ:
- Нужен скрипт собиратель версий, который будет запускаться на каждом контуре и собирать версии, после чего пушить их, например в отдельно заведенный нами репозиторий. Пусть репозиторий будет называться «components-version».
- Нужен скрипт публикатор, который заберт репу с версиями из репозитория и на основе нее сделает магию и запушит в Confluence. Его достаточно запускать на каком-то одном контуре. Запускать будем также по крону в кубере.
Окей, ТЗ составлено, давайте немного по скриптуем. Сразу скажу, что это старые мои наработки, не факт, конечно, что сейчас я написал бы лучше, но хочется верить.
Собираем версии с контуров:
#!/usr/bin/env python3.8
from kubernetes import client, config
import sys
import re
from git import Repo
from git import Git
import shutil
import os
try:
ns = sys.argv[1]
except IndexError:
print(f"Usage: {sys.argv[0]} <namespace>")
sys.exit(1)
result_file = f"{ns}.txt"
repo_url = "<you_git_repo>"
git_clone_dir = "/tmp/devops-components-version"
if ns == "dev" or ns == "test":
config.load_kube_config(config_file='./config_dev')
elif ns == "prod":
config.load_kube_config(config_file='./config_prod')
v1 = client.AppsV1Api()
deployment = v1.list_namespaced_deployment(ns)
def get_component_and_version():
print(f"[+] Get component version from namespace {ns}...")
file = open(result_file, 'w')
char_for_delete = "[']"
for item in deployment.items:
image = str(re.findall(r'<you_repo>/project>.*\w', str(item.spec)))
for char in char_for_delete:
image = image.replace(char, "")
if image == "":
continue
elif (",") in image:
full_app = image.split(",")[0]
full_app = full_app.split("/")[2]
file.write(full_app + '\n')
else:
full_app = image.split("/")[2]
file.write(full_app+'\n')
file.close()
def clone_repository(repo, dir):
print(f"[+] Cloning repository {repo} to {dir}...")
git_dir_is_exist = os.path.exists(dir)
if not git_dir_is_exist:
os.makedirs(dir)
shutil.rmtree(dir)
Repo.clone_from(repo, dir, env=dict(GIT_SSH_COMMAND="ssh -i ./private_ssh_key -o StrictHostKeyChecking=no"))
def main():
get_component_and_version()
clone_repository(repo_url, git_clone_dir)
shutil.copy(result_file, git_clone_dir)
print(f"[+] Push changes to {repo_url}...")
repo = Repo(git_clone_dir)
with repo.git.custom_environment(GIT_SSH_COMMAND="ssh -i /opt/private_ssh_key"):
repo.git.add(update=True)
repo.index.commit("Update devops-component-version")
repo.git.push('origin', 'master')
print("[+] Successfully...")
if __name__ == "__main__":
main()Это весь код нашего сборщика. Давайте пройдемся по нему
try:
ns = sys.argv[1]
except IndexError:
print(f"Usage: {sys.argv[0]} <namespace>")
sys.exit(1)
result_file = f"{ns}.txt"
repo_url = "<you_git_repo>"
git_clone_dir = "/tmp/devops-components-version"
if ns == "dev" or ns == "test":
config.load_kube_config(config_file='./config_dev')
elif ns == "prod":
config.load_kube_config(config_file='./config_prod')
v1 = client.AppsV1Api()
deployment = v1.list_namespaced_deployment(ns)В начале реализуем то, что лучше делать через argparse, т.е. некое подобие CLI.
Обозначаем несколько переменных, конкретно в моем случае, контур «dev», «test» и не разные контуры вовсе, а один, просто это разные namespace-ы, поэтому мы подкладываем им один и тотже kubeconfig. В целях безопасности, естественно нужно держать этот kubeconfig в VAULT и во время работы скрипта получать его оттуда, а еще лучше чтобы этот kubeconfig имел доступ только к нужным для работы скрипта namespace-ам.
Далее создаем объект для работы с k8s api.
Метод get_component_and_version() — метод открывает на запись файл {result_file}, пробегается циклом по нашим сущностям deployments и пишет в файл строки, начиная с новой строки вида <имя>:<версия>
Остальное относительно легко читается, мы клонируем репозиторий с помощью ssh ключа, делаем комит и пуш.
Давайте сделаем Dockerfile с этим добром:
FROM python:3.8-slim
WORKDIR /opt
COPY updater-version/configs/get_component_version.py ./
COPY updater-version/configs/* ./
RUN chmod 0600 private_ssh_key
RUN apt-get update && apt-get install -y ansible git openssh-client
RUN pip3 install -r requirements.txt
RUN secret=$(cat secret-file.txt|base64 -d) && sed 's/.*/'$secret'/' -i secret-file.txt && ansible-vault decrypt config_dev config_prod --vault-password-file secret-file.txt
ENTRYPOINT ["python3.8", "/opt/get_component_version.py"]RUN secret= — зачем тут этот ужас? Все дело в том, что на тот момент это был пилотный проект, не было ни волта, ни чего то еще, откуда можно было бы по devops way забрать что-то секретное. Поэтому пришлось выдумать «иллюзию» безопасности, где в репе лежит base64 закодированный текс, который используется для раскодирования с помощью ansible-vault кубер конфигов.
Да, это максимально странно, но иногда бывает и такое.
Давайте напишем helm chart для деплоя.
Values.yaml
app_value:
schedule: "@hourly"
restartPolicy: "Never"
imageRepo: "<you_repo>"
imageName: "updater-version"
imageTag: "1.1-7"
successfulJobsHistoryLimit: "1"
failedJobsHistoryLimit: "1"Cronjob.yaml
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: {{ include "updater-version.name" . }}
spec:
schedule: {{ .Values.app_value.schedule | quote }}
successfulJobsHistoryLimit: {{ .Values.app_value.successfulJobsHistoryLimit }}
failedJobsHistoryLimit: {{ .Values.app_value.failedJobsHistoryLimit }}
jobTemplate:
spec:
template:
spec:
imagePullSecrets:
- name: <secret_name>
containers:
- name: {{ include "updater-version.name" . }}
{{ if .Values.app_value.imageTag }}
image: "{{ .Values.app_value.imageRepo }}/{{ .Values.app_value.imageName }}:{{ .Values.app_value.imageTag }}"
{{ else }}
image: "{{ .Values.app_value.imageRepo }}/{{ .Values.app_value.imageName }}"
{{ end }}
args:
- {{ .Release.Namespace | quote }}
restartPolicy: {{ .Values.app_value.restartPolicy }}Тут все максимально типично, не будем заострять на этом внимание.
Тут можно посмотреть полный код и конфиги для этого функционала.
Проверили, задеплоили, оно работает, собирает версии. Можно ехать дальше.
Пишем аптейтер странички на Confluence:
from atlassian import Confluence
import yaml
from git import Repo
from git import Git
import shutil
import os
import urllib3
from urllib3.exceptions import InsecureRequestWarning
urllib3.disable_warnings()
kb_url = "<you_kb_url>"
config_file = "/opt/auto_jira_update.yaml"
page_id = "<you_page_id>"
data = {"dev": {}, "test": {}, "prod": {}}
lose_app = []
repo_url = "<git_url_with_components_version>"
git_clone_dir = "/tmp/devops-components-version"
kb_login = os.environ.get("CF_LOGIN")
kb_password = os.environ.get("CF_PASSWORD")
def get_repo_info(repo_url, repo_clone_dir):
print(f"[INFO] Cloning repository {repo_url} into {repo_clone_dir}...")
clone_dir_exist = os.path.exists(repo_clone_dir)
if not clone_dir_exist:
os.makedirs(repo_clone_dir)
shutil.rmtree(repo_clone_dir)
Repo.clone_from(repo_url, repo_clone_dir, env=dict(GIT_SSH_COMMAND="ssh -i /opt/private_ssh_key -o StrictHostKeyChecking=no"))
for file in data.keys():
file_path = repo_clone_dir + "/" + file + ".txt"
with open (file_path, 'r', encoding="utf-8") as f:
for item in f:
app_name = item.split(":")[0]
app_version = item.split(":")[1]
data[file][app_name] = app_version
return data
def post_content(data, page_id, kb):
table_body = ""
table_body += """<table class="wrapped relative-table" style="width: 70%;"><colgroup><col style="width: 70%;"/><col style="width: 30%;"/></colgroup><tbody>"""
table_body += "<tr><th>Component</th>"
for ns in data.keys():
table_body += f"<th>{ns}</th>"
table_body += "</tr>"
for app in sorted(data["dev"]):
table_body += f"<tr><td>{app}</td><td>{data['dev'][app]}</td>"
try:
if data['dev'][app] != data["test"][app]:
table_body += f"<td>{data['test'][app]}</td>"
else:
table_body += f"<td>{data['test'][app]}</td>"
except KeyError as e:
table_body += "<td>null</td>"
try:
if data['dev'][app] != data["prod"][app]:
table_body += f"<td>{data['prod'][app]}</td>"
else:
table_body += f"<td>{data['prod'][app]}</td>"
except KeyError as e:
table_body += "<td>null</td>"
table_body += "</tr>"
table_body += """</tbody></table>"""
table_body += """<p class="auto-cursor-target"><br /></p>"""
kb.update_page(page_id, title="Installed Componet version", body=table_body, parent_id=None, type='page', representation='storage', minor_edit=False)
def main():
kb = Confluence(url=kb_url, username=kb_login, password=kb_password, verify_ssl=False)
data = get_repo_info(repo_url, git_clone_dir)
post_content(data, page_id, kb)
print("[INFO] Update success.")
if __name__ == "__main__":
main()Давайте пробежимся по методам.
get_repo_info() — тут мы пуллим наш репозиторий с версиями и на основании его создаем словарь с маппингом.
post_content() — основной метод, здесь тут мы пробигаемся циклом по словарю, реализуем логику с проверкой других ключей в словаре (они соответствуют контурам), если какого-то значения не нашлось, то мы присваиваем переменной значение null, далее все это мы постим в Confluence.
В итоге у нас получается вот такая таблица.
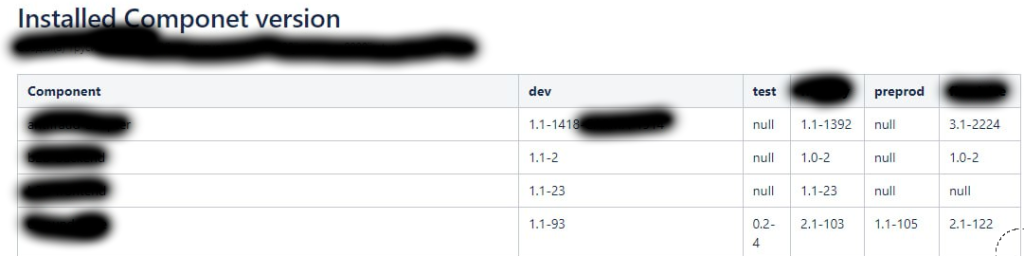
В колонке «Components» — наши имена микросервисов, другие колонки разбиты по именованию контуров приложения. Если какого-то микросервиса нет на контуре, то в колонке будет null.
Полный код всего этого добра можно посмотреть тут.



{kind=link}