При использование nerdctl во время первого «пуллинга» образа, если произойдет что-либо на сети или у registy, мы можем получить условно «битый» образ и при попытке повторого pull увидеть ошибку. Такое периодически бывает при развертывании k8s через kubespray.

Пофиксить достаточно просто, нужно найти проблемный слой на ФС, удалить его и перезапустить то, что мы используем как CRI (Container Runtime Interface).
У меня использовался containerd.
Ищем хеш на ФС, удалем его и перезапускаем containerd. Потом делаем заново pull:
Bash
ls -l /var/lib/containerd/io.containerd.content.v1.content/ingest
rm -rf /var/lib/containerd/io.containerd.content.v1.content/ingest/<hash>
systemctl restart containerd
nerdctl -n <ns> pull <image>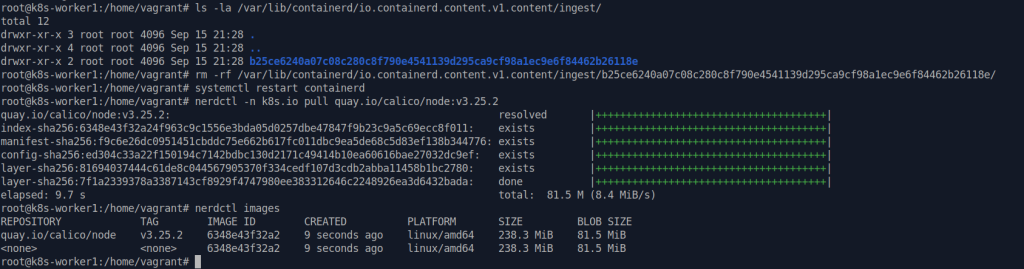


{kind=link}