Собственно сегодня будем делать микросервис, который будет заниматься очисткой образов в gitlab registry. Образы будет чистить не все, а только у тех проектов, который мы укажем в конфиге, а также укажем там время очистки, например чистить старше чем 2 дня, 5 часов, 60 минут. Пока эти три типа будут поддерживаться. И тут стоит сразу оговориться что gitlab registry, как и многие другие, могут «некорректно» проставлять поле «created_at» при push образа. Дело в том, что если ни один слой не меняется, то digest образа будет неизменный и дата создания выставится не текущая, даже если вы только что сделали push образа. Поэтому в своем примере я буду использовать простую записать вывода команды date в файл, тем самым один слой всегда будет перестраиваться и дата создания образа будет корректна.
Работать будет с JSON конфигурационным файлов. Вот пример:
{
"gitlab_project_1":
{
"id": 1,
"delete_older_than": {
"days": 2
}
},
"gitlab_project_2":
{
"id": 2,
"delete_older_than": {
"hours": 5
}
},
"gitlab_project_3":
{
"id": 3,
"delete_older_than": {
"minutes": 60
}
}
}Здесь ключом будет являться имя проекта, оно может быть произвольным и сделано для понимания и удобства логирования.
id — это PROJECT_ID проекта в gitlab.
delete_older_than — параметр, в котором указываем дни, часы или минуты старше которых мы будем удалять образ. Данное поле будем в коде преобразовывать в timedelta, но об этом чуть позже.
Структура проекта в PyCharm
Сборкой и версионированием будем управлять через poetry. Инициализируем конфиг и добавил нужные библиотеки.
poetry add httpx asyncio python-dotenv
poetry add black --group devВ dev зависимости добавить код форматтер black. Отличный инструмент, уже интегрирован в PyCharm. Найти можно в настройках и нажать нужные галки, будет форматирование кода, согласно обще принятому в python сообществе.
Код для удобства и дальнейшего расширения разобьем на пакеты. Вообще для работы с gitlab есть библиотека python-gitlab, но она построена на requests под капотом и является синхронной, то есть не подойдет для наших задач. Асинхронную библиотеку для gitlab я не нашел, да и в целом это не нужно, у нас будет парочка GET запросов и DELETE.
Выделим пакет api_requests для отправки запросов.
Для создания CLI пакет так и назовем cli.
Еще нам понадобится читать конфигурационный JSON файл и преобразовывать его в python объект, то есть сделать десериализацию. Для этого заведем пакет config_reader.
Отдельный пакет gitlab собственно для работы с gitlab API. И пакет logger, для реализации логирования.
Пока думаю хватит.
Пакет CLI.
"""CLI module."""
import argparse
import os
from dataclasses import dataclass
@dataclass
class GitlabConfig:
"""Gitlab parameters."""
gitlab_token: str
gitlab_url: str
config: str
dry_run: bool
ssl_path: str
timeout: int
def create_parser() -> tuple[argparse.ArgumentParser, GitlabConfig]:
"""CLI parser method."""
parser = argparse.ArgumentParser(description="Gitlab registry cleaner")
parser.add_argument(
"-t",
"--token",
dest="gitlab_token",
required=False,
default=os.environ.get("GITLAB_TOKEN"),
help="Gitlab token",
)
parser.add_argument(
"-u",
"--url",
required=False,
dest="gitlab_url",
default=os.environ.get("GITLAB_URL"),
help="GITLAB URL",
)
parser.add_argument(
"-c",
"--config",
dest="config",
required=False,
default=os.environ.get("REPOSITORY_CONFIG_PATH"),
help="Path to gitlab repository config",
)
parser.add_argument(
"-d",
"--dry-run",
dest="dry_run",
required=False,
action="store_true",
help="Run in dry run mode. Without delete tags.",
)
parser.add_argument(
"--ssl-path",
dest="ssl_path",
required=False,
default=os.environ.get("SSL_PATH", False),
help="Path to SSL gitlab certificate.",
)
parser.add_argument(
"--timeout",
dest="timeout",
required=False,
default=os.environ.get("TIMEOUT", 20),
help="HTTP request timeout.",
)
args = parser.parse_args()
config = GitlabConfig(
gitlab_token=args.gitlab_token,
gitlab_url=args.gitlab_url,
config=args.config,
dry_run=args.dry_run,
ssl_path=args.ssl_path,
timeout=args.timeout,
)
return parser, config
Здесь мы реализуем класс GitlabConfig, чтобы хранить «стейт» и передавать данные через код в виде одного объекта а не кучи параметров. Возвращать будем помимо нашего экземпляра класса еще и parser, чтобы мочь вызвать там где нам нужно метод print_help().
Пакет логирования.
"""Logger module."""
import logging
import json
class JSONFormatter(logging.Formatter):
"""Custom json formatter"""
def __init__(self):
"""Override class."""
super().__init__()
def format(self, record):
"""Custom log format."""
log_record = {
"module": record.name,
"asctime": self.formatTime(record, self.datefmt),
"levelname": record.levelname,
"message": record.getMessage(),
}
if hasattr(record, "operation"):
log_record["operation"] = record.operation
if hasattr(record, "tag_name"):
log_record["tag_name"] = record.tag_name
if hasattr(record, "tag_location"):
log_record["tag_location"] = record.tag_location
return json.dumps(log_record, ensure_ascii=False)
class Logging:
"""Init logger class."""
def __init__(self, logger_name: str):
"""Constructor."""
self.logger_name = logger_name
self.logger = logging.getLogger(self.logger_name)
self.logger.setLevel(logging.INFO)
formatter = JSONFormatter()
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
console_handler.setFormatter(formatter)
self.logger.addHandler(console_handler)
def log(self, level, message, *args, **kwargs):
"""General log method."""
extra = kwargs.get("extra", {})
self.logger.log(level, message, *args, extra=extra)
def info(self, message, *args, **kwargs):
"""INFO."""
self.log(logging.INFO, message, *args, **kwargs)
def debug(self, message, *args, **kwargs):
"""DEBUG."""
self.log(logging.DEBUG, message, *args, **kwargs)
def warning(self, message, *args, **kwargs):
"""WARNING."""
self.log(logging.WARNING, message, *args, **kwargs)
def error(self, message, *args, **kwargs):
"""ERROR."""
self.log(logging.ERROR, message, *args, **kwargs)
def critical(self, message, *args, **kwargs):
"""CRITICAL."""
self.log(logging.CRITICAL, message, *args, **kwargs)
Из интересно, тут я добавил еще именных аргументов, дело в том, что при определенных операциях, например удаления, было бы неплохо писать не просто текст, а отдельное поле, чтобы потом например в Кибане это все можно было легко искать. Поэтому тут и есть проверка с hasattr, так как эти поля мы добавлять хотим не всегда. Если проверку не делать и просто пихнуть их в log_record с каким-нибудь дефолтом None, то собственно его и получим в логах, в которых явно не передаем дополнительные аргументы.
Пакет api_request:
from typing import Optional
import httpx
from gitlab_registry_async_cleaner.logger.logger import Logging
logger = Logging(__name__)
async def send_api_get_request(**kwargs) -> httpx.Response | None:
"""Send GET request to URL with some re-try."""
async with httpx.AsyncClient(verify=kwargs.get("verify", False)) as client:
for _ in range(int(kwargs.get("max_retries", 5))):
try:
response = await client.get(
url=kwargs.get("url"),
headers=kwargs.get("headers", None),
timeout=int(kwargs.get("timeout", 20)),
params=kwargs.get("params", None),
)
return response
except httpx.RequestError as err:
logger.error(
"Failed GET request on %s. Error: %s",
kwargs.get("url"),
err,
)
await asyncio.sleep(5)
logger.error(
"Failed GET request after %s retries on %s",
kwargs.get("max_retries", 5),
kwargs.get("url"),
)
return NoneТут мы создаем экземпляр класса Logging глобально и передаем в него __name__, что будет соответствовать имени пакет.модуль. Пример лога
{"module": "gitlab_registry_async_cleaner.tag_handler", "asctime": "2024-08-27 20:06:48,554", "levelname": "INFO", "message": "Start processing project: repo_1"}Также делаем ретрай из 5 попыток, если вдруг что-то пошло не так. Для асинхронных запросов я использую httpx, он максимально простой и очень похож на requests. Переход практически не заметен.
Пакет config_reader.
"""config reader module."""
import json
import sys
from typing import Any
from gitlab_registry_async_cleaner.logger.logger import Logging
logger = Logging(__name__)
def read_json_config(json_config_path: str) -> Any:
"""Read json config."""
if json_config_path:
try:
with open(json_config_path, encoding="utf-8") as file:
json_config = json.load(file)
return json_config
except FileNotFoundError:
logger.error("File %s not found.", json_config_path)
sys.exit(1)
else:
logger.error("Argument --config is empty.")
return None
Ну, тут особо ничего интересно и нет.
Чтобы было проще понять логику работы кода, далее продолжим рассматривать с основного main модуля.
"""Main module."""
import asyncio
import os
import sys
from dotenv import load_dotenv
from gitlab_registry_async_cleaner.cli.cli import create_parser
from gitlab_registry_async_cleaner.config_reader.config_reader import read_json_config
from gitlab_registry_async_cleaner.tag_handler import create_async_tasks
load_dotenv(dotenv_path=os.path.join(os.getcwd(), ".env"))
parser, config = create_parser()
async def async_main():
"""Run async function."""
json_config = read_json_config(config.config)
if json_config is None:
parser.print_help()
sys.exit(1)
await create_async_tasks(json_config=json_config, config=config)
def main():
"""Entry point."""
asyncio.run(async_main())
if __name__ == "__main__":
main()
Тут мы читаем .env файл в директории запуска, это нужно тогда, когда мы не хотим передавать никаких аргументов и просто хотим запустить скрипт. Также можно задать переменные где-то выше на хосте, контейнере и так далее просто переменными окружения. В CLI, мы учитываем переменные окружения и по дефолту берем значения оттуда, если они не определены как аргументы cli при запуске скрипта.
Здесь мы запускаем создание асинхронных задач из модуля tag_handler. Он лежит рядом с main и его я не стал выносить в отдельный пакет.
async def create_async_tasks(
json_config: dict,
config: GitlabConfig,
) -> None:
"""Create async tasks to clean project repos."""
headers = {"PRIVATE-TOKEN": config.gitlab_token}
tasks = []
for name, value in json_config.items():
repo_name = name
repo_id = value["id"]
repo_delete_older_than = value["delete_older_than"]
repo_delete_delta = await convert_to_timedelta(repo_delete_older_than)
logger.info("Start processing project: %s", repo_name)
tasks.append(
process_project(
repo_name=repo_name,
repo_id=repo_id,
repo_delete_delta=repo_delete_delta,
headers=headers,
config=config,
)
)
results = await asyncio.gather(*tasks, return_exceptions=True)
for result in results:
if isinstance(result, Exception):
logger.error("Error in process_project task: %s", result)В этой функции мы добавляем в список выполнение другой функции и запускаем их асинхронной через asyncio. Это нужно, так как мы читаем в цикле наш конфиг, то есть последовательно и никакой асинхронности бы не было, если бы мы просто дальше написали код. Обязательно используем return_exceptions=True для метода gather, иначе если в нашей задаче будет исключение, то все остальные задачи будут отменены.
async def process_project(
repo_name: str,
repo_id: int,
repo_delete_delta: timedelta,
headers: dict,
config: GitlabConfig,
) -> None:
"""Processing project."""
registry_repository = await get_repositories(
registry_project_id=repo_id,
headers=headers,
config=config,
)
if registry_repository is not None:
for repository_id, _ in registry_repository.items():
await process_tags(
registry_project_id=repo_id,
repository_id=repository_id,
headers=headers,
config=config,
delete_older_than=repo_delete_delta,
)
else:
logger.error("Can't get data from repository %s", repo_name)Запуск этой функции мы вызываем асинхронно, из предыдущей. Это значит что при прочтении данных из конфигурационного файла, на его основе будет создано ровно столько асинхронных задач, сколько ключей в конфиге. Дальше по коду мы получаем список репозиториев у registry в проекте. В контексте гитлаба, в рамках проектного registry может быть много репозиториев, каждый со своим id.
Вот как это выглядит в UI
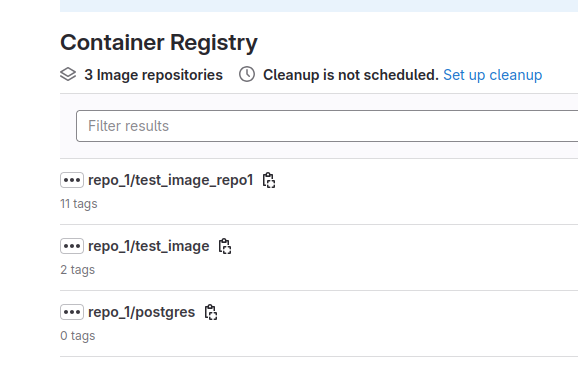
API у гитлаба как-бы слоями. Сначала мы получаем список репозиториев, в котором есть ID этих самых репозиториев. Дальше мы по ID репозитория получаем список всех тегов и затем только мы можем получить имя тега. Я формирую URL-ы для этого динамически, вот так
"""Render gitlab api urls module."""
def get_repositories_url(gitlab_url: str, project_id: int) -> str:
return f"{gitlab_url}/api/v4/projects/{project_id}/registry/repositories"
def get_tags_url(gitlab_url: str, project_id: int, repository_id: int) -> str:
return f"{gitlab_url}/api/v4/projects/{project_id}/registry/repositories/{repository_id}/tags"
def get_single_tag_url(
gitlab_url: str, project_id: int, repository_id: int, tag_name: str
) -> str:
return f"{gitlab_url}/api/v4/projects/{project_id}/registry/repositories/{repository_id}/tags/{tag_name}"
Здесь хорошо виден этот слоеный пирог.
Далее мы вызовем функцию process_tags и из нее будет вызывать другие функции в модуле image_repository_process пакета gitlab. Я думал над тем, чтобы уйти от этого, разделить логику, оставив в модуле только получения данных, а всю обработку в другом месте, но кажется это напротив бы усложнило код, пришлось бы собирать эти данные, формировать структуры данных, которые потом отдельно обрабатывать, да и это сказалось бы на быстродействии, поэтому решил оставить так.
async def process_tags(
registry_project_id: int,
repository_id: int,
headers: dict,
config: GitlabConfig,
delete_older_than: timedelta,
) -> None:
"""Processing tags in repositories."""
url = get_tags_url(
gitlab_url=config.gitlab_url,
project_id=registry_project_id,
repository_id=repository_id,
)
data = await send_api_get_request(
url=url,
timeout=config.timeout,
headers=headers,
verify=config.ssl_path,
)
if data is not None:
if data.status_code == 200:
tasks = []
total_page_number = int(data.headers["X-Total-Pages"])
current_page_number = int(data.headers["X-Page"])
while current_page_number <= total_page_number:
response = await send_api_get_request(
url=url,
timeout=config.timeout,
headers=headers,
verify=config.ssl_path,
params={"page": current_page_number},
)
repository_tags = response.json()
for _, item in enumerate(repository_tags):
tag_name = item["name"]
tasks.append(
process_single_tag_and_delete(
registry_project_id=registry_project_id,
repository_id=repository_id,
tag_name=tag_name,
headers=headers,
config=config,
delete_older_than=delete_older_than,
)
)
current_page_number += 1
results = await asyncio.gather(*tasks, return_exceptions=True)
for result in results:
if isinstance(result, Exception):
logger.error("Error occurred during tag processing: %s", result)
else:
logger.error(
"Failed request to %s with status: %s and message: %s",
url,
data.status_code,
data.text,
)
else:
logger.error("Failed read data from %s", url)Здесь мы получаем теги, делаем пагинацию, так как gitlab не отдаст сразу например 1000 тегов если у нас столько есть, после создаем отдельные таски как и раньше для асинхронной обработки тегов.
async def process_single_tag_and_delete(
registry_project_id: int,
repository_id: int,
tag_name: str,
headers: dict,
config: GitlabConfig,
delete_older_than: timedelta,
) -> None:
"""Process single tag and delete if need."""
url = get_single_tag_url(
gitlab_url=config.gitlab_url,
project_id=registry_project_id,
repository_id=repository_id,
tag_name=tag_name,
)
tag_info = await send_api_get_request(
url=url,
timeout=config.timeout,
headers=headers,
verify=config.ssl_path,
)
if tag_info is not None:
if tag_info.status_code == 200:
tag_info = tag_info.json()
is_tag_mark_to_delete = await is_tag_expired(
tag_created=tag_info["created_at"], delete_older_than=delete_older_than
)
logger.info(
"Processing repository tag.",
extra={
"operation": "processing",
"tag_location": tag_info["location"].rsplit(":", 1)[0],
"tag_name": tag_info["name"],
},
)
if is_tag_mark_to_delete:
await delete_tag(
registry_project_id=registry_project_id,
repository_id=repository_id,
tag_name=tag_name,
headers=headers,
config=config,
tag_path=tag_info["location"].rsplit(":", 1)[0],
)
else:
logger.error(
"Failed request to %s. Status: %s. Message: %s",
url,
tag_info.status_code,
tag_info.text,
)
else:
logger.error("Failed read data from %s", url)В этой функции примерно тоже самое, только работаем мы уже с отдельным тегом, который проверяем согласно нашему правилу очистки из конфига.
async def is_tag_expired(tag_created: str, delete_older_than: timedelta) -> bool | None:
"""Check if tag is expired."""
try:
tag_date = datetime.fromisoformat(tag_created)
now = datetime.now(timezone.utc)
return tag_date < now - delete_older_than
except TypeError:
logger.warning("Can't read created_at filed: Value: %s", tag_created)Здесь мы проверяем, старше тег или нет, чем указанное нами время в конфиге. Если тег старше, мы возвращаем True, что означает что тег можно удалить.
А конвертируем наш конфиг в timedelta мы вот таким простым способом.
async def convert_to_timedelta(repo_delete_older_than: dict) -> timedelta:
"""Convert dict to timedelta."""
if "days" in repo_delete_older_than:
return timedelta(days=repo_delete_older_than["days"])
if "hours" in repo_delete_older_than:
return timedelta(hours=repo_delete_older_than["hours"])
if "minutes" in repo_delete_older_than:
return timedelta(minutes=repo_delete_older_than["minutes"])
else:
raise ValueError("Unsupported time unit %s", repo_delete_older_than)Проверка работы.
Конфиг файл.
$ cat registry_config.json
{
"repo_1":
{
"id": 1,
"delete_older_than": {
"days": 2
}
},
"repo_2":
{
"id": 2,
"delete_older_than": {
"minutes": 50
}
},
"repo_3":
{
"id": 3,
"delete_older_than": {
"minutes": 2
}
}
}
Тестовый Dockerfile
FROM alpine:latest
ARG BUILD_DATE
LABEL org.opencontainers.image.created=$BUILD_DATE
RUN date -u > /build_date.txtСобираем и пушем в цикле, чтобы было по больше тегов с уникальной (на момент создания) датой.
for i in {0..10};do docker build --no-cache --build-arg BUILD_DATE=$(date -u +"%Y-%m-%dT%H:%M:%SZ") -t 192.168.10.202:5005/root/repo_2/test_image_repo_2:$i .; docker push 192.168.10.202:5005/root/repo_2/test_image_repo_2:$i;doneТут меняем как нам нужно параметры, чтобы сошлось тегирование образа с его пушем.
В registry будет что-то вроде этого.
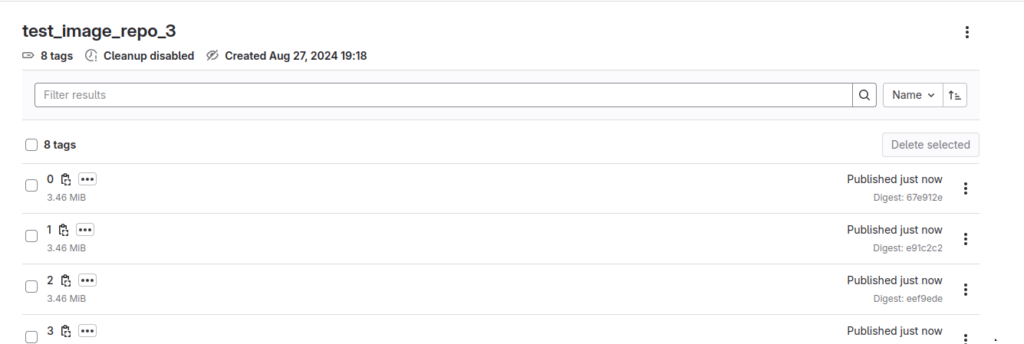
Итого, у меня по регистри получилась следующая картина.
repo_1.
Много репозиториев с одним тегом и датой создания 5 минут назад +- на момент запуска скрипта. И парочка тегов с датой создания 1 день назад.
Помним, что для этого репозитория мы поставили удалять все, что страше двух дней. То есть ничего удалено быть не должно.
repo_2.
Куча репозиторией с одним тегом и датой создания 1 час назад + 11 тегов в репе с датой +- 5 минут назад. Поставим для удаления старше 50 минут.
repo_3.
11 тегов в одном репозитории старше 5 минут. Поставим удалять старше 2-х.
Сначала запустим в dry-run режиме. Это тоже самое, только по факту теги удалены не будут.
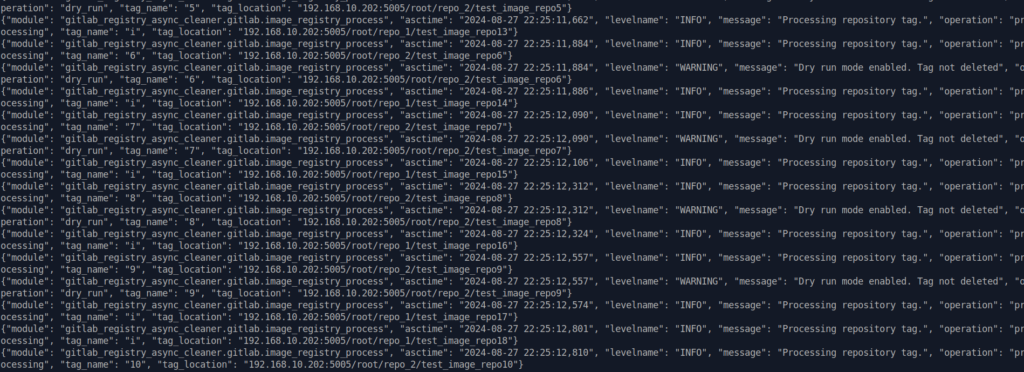
Работает асинхронно и достаточно быстро.
Запускаем в боевом режиме с реальным удалением тегов.
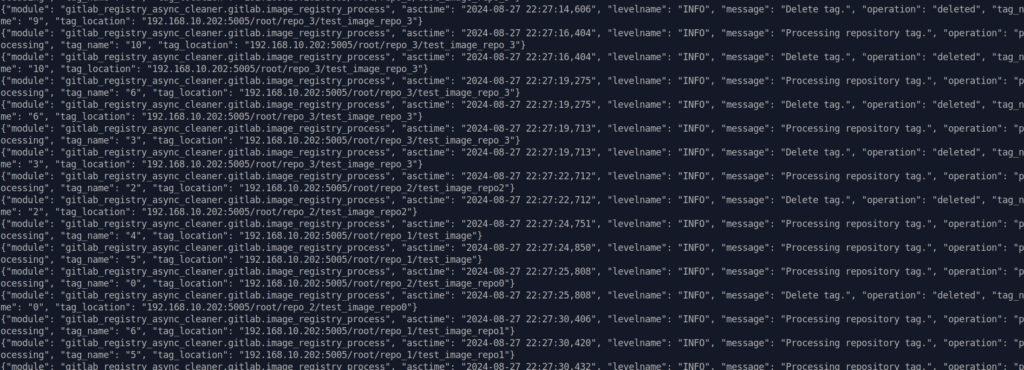
Теги были удалено ровно так, как ожидалось. Также по таймингу можно заметить ту самую асинхронность.
Установить утилиту можно так
pip install gitlab_registry_async_cleanerЗапуск.
gitlab_async_cleanerСтраница на PyPi.
Полный код на github.



{kind=link}